From pattern to prototype: building the Phase 01 research orchestrator
From pattern to prototype: building the Phase 01 research orchestrator
A follow-up to Agentic AI is coming to the SaMD lifecycle.
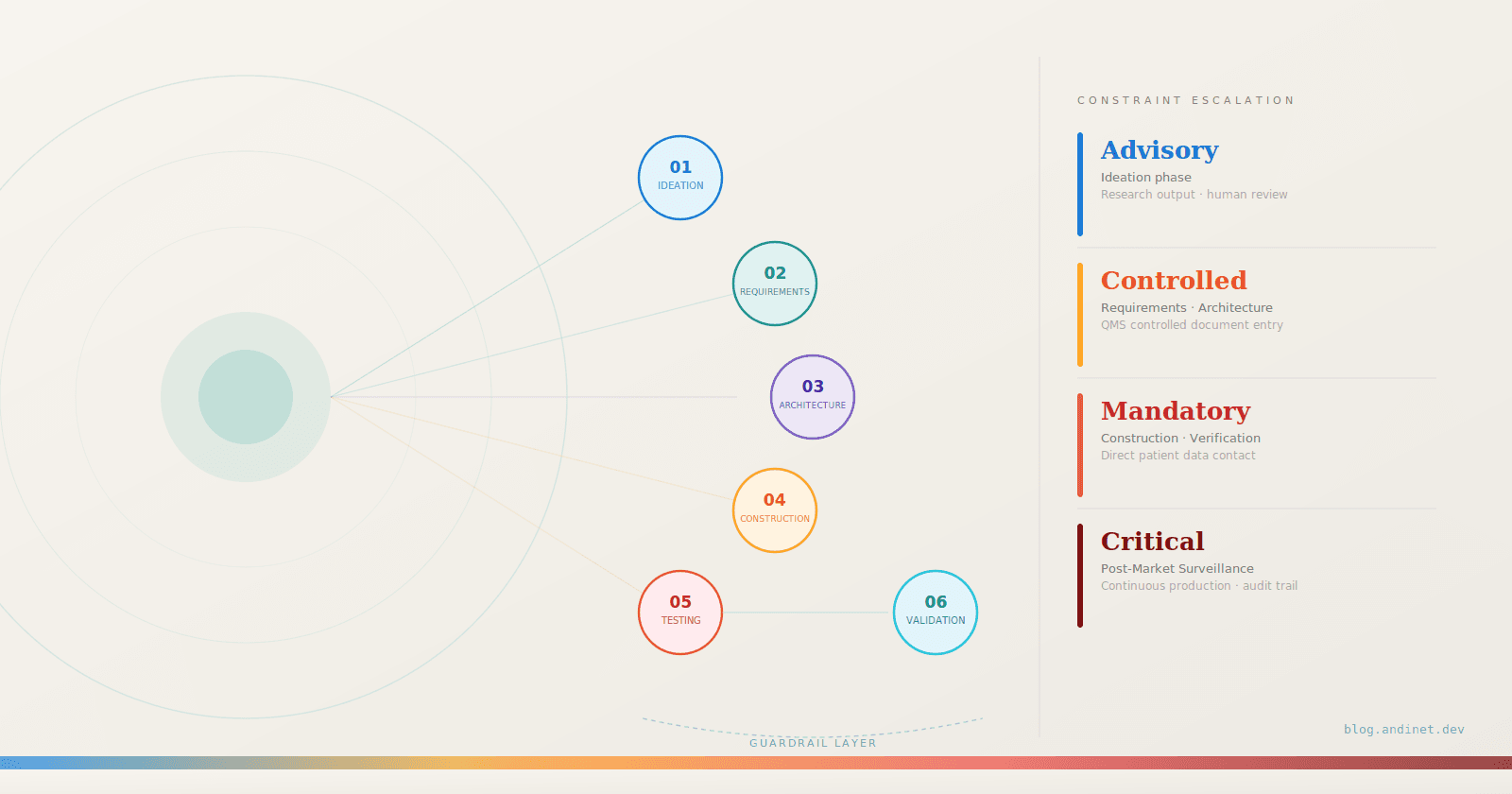
In the first post I sketched six phases of the Software-as-a-Medical-Device lifecycle and, for each, a proposed agent pattern. Those were designs on paper. The obvious question — from readers and from myself — was: can you actually build one of these?
This post answers that for Phase 01: Ideation and User Needs. I picked a concrete clinical target — an AI tool that detects and triages pulmonary nodules on chest CT — wired the proposed orchestrator up to the real FDA and NIH databases, and let it produce an actual gap-analysis document. Everything below comes from a real run against live APIs; the code is in the companion repo — github.com/andinet/nodule-scout — and it runs on the Claude Agent SDK.
A necessary caveat up front: this is a conceptual ideation aid, not validated SaMD, and it produces no clinical guidance. The point is to make the pattern — and its guardrails — concrete and inspectable.
TL;DR
- The Phase 01 research-orchestrator pattern from the first post is buildable today — I wired it to real FDA and NIH APIs and it produces a genuine, fully-cited gap analysis in a few hundred lines.
- The guardrails are the product. A deterministic citation validator rejects any claim the model can't trace to a fetched record — so the output is auditable by construction, not by trust.
- The friction is the data, not the agents. MAUDE is sparse and the "CAD" acronym collides with dental CAD/CAM — and surfacing that is itself a valid Phase 01 finding.
- Code, tests, and a committed sample run: github.com/andinet/nodule-scout.
THE PROPOSED AGENT PATTERN (recap)
From Phase 01: a research orchestrator decomposes a broad clinical question into sub-tasks and dispatches them to specialized tool-calling sub-agents. One sub-agent searches PubMed for recent literature. Another mines the FDA's MAUDE adverse-event database for software failures in similar products. A third pulls predicate-device labeling from the FDA 510(k) database. The orchestrator collects the results, grounds them in the company's internal clinical-advisory notes via RAG, and produces a structured gap-analysis document.
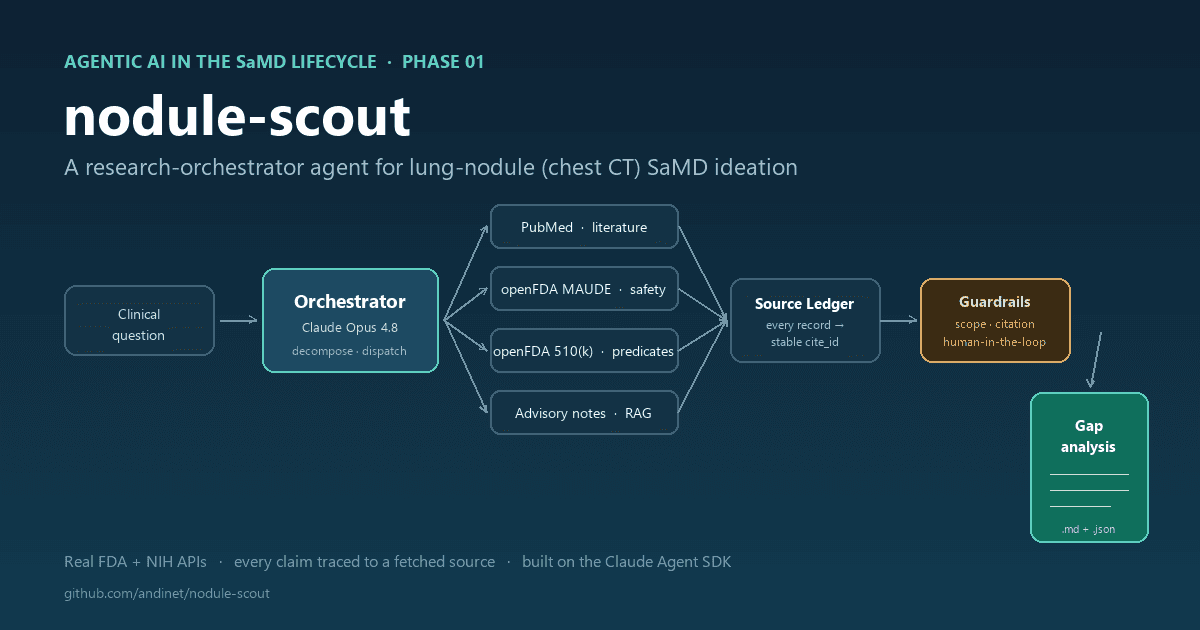
Here is that pattern, as built:
clinical question ─▶ ORCHESTRATOR (Claude Opus 4.8)
decompose → dispatch → ground → synthesize
┌───────────────────┼────────────────────┐
pubmed-researcher maude-analyst predicate-analyst + RAG over
(PubMed E-utils) (openFDA MAUDE) (openFDA 510(k)) advisory notes
└─────────── Source Ledger (every fetched record) ──────┘
│
guardrails: scope · citation · human-in-the-loop
│
gap_analysis.md
Figure 1 — The Phase 01 research-orchestrator pattern, as built.
The pleasant surprise: all three external sources are free public APIs with no authentication — PubMed E-utilities, openFDA MAUDE, and openFDA 510(k). So the pattern is genuinely end-to-end runnable, not a mock.
What the Tools Actually Returned
Each sub-agent owns exactly one skill, which is a thin wrapper over a real endpoint. From one run of the deterministic pipeline, the orchestrator pulled 46 real records into the run's source ledger:
- PubMed surfaced current work like the LUNA25 benchmark comparing AI to radiologists on indeterminate-nodule malignancy risk, and a 2026 systematic review of externally-tested lung-nodule classification models that flags unsettled generalizability.
- 510(k) returned a crowded, fast-moving predicate field — Fujifilm Synapse Lung Nodule AI, Coreline AVIEW, Riverain ClearRead CT, RevealAI-Lung, Infervision — cleared across several different product codes (OEB, POK, JAK), which turns out to matter (more below).
- MAUDE was the interesting one. There is almost no adverse-event data for AI lung-nodule devices, and the keyword "CAD" collides with dental CAD/CAM, so most retrieved records are dental restoration systems. That noisiness is itself a Phase 01 finding — you cannot yet characterize the real-world failure-mode distribution of these devices from MAUDE, and the orchestrator reported exactly that rather than inventing a signal.
Then a lightweight RAG step (BM25 over a small synthetic advisory-notes corpus) pulled the internal clinical concerns most relevant to the question — subsolid-nodule performance, false-positive tolerance in screening vs incidental contexts, PACS/worklist integration, and the detection-vs-risk-vs-recommendation intended-use boundary.
GUARDRAILS AND EVALUATION
The first post argued that the guardrails matter more than the plumbing. This is where the prototype earns its keep. Three layers:
1. Scope constraint. Ask the orchestrator an off-domain question and it refuses before spending anything:
$ python run.py "What are the unmet needs in breast MRI triage software?"
[scope] Off-domain terms ['breast'] with no lung-nodule anchor.
Refusing: question is out of the lung-nodule SaMD scope.
2. Source attribution — the load-bearing one. Every record any tool fetches
is stored in a run-scoped Source Ledger under a stable citation id
(PMID:42340186, K254075, MAUDE:11195257, NOTE:subsolid-nodules). The gap
analysis is emitted through a submit_gap_analysis tool, and a deterministic
validator — not the model's own say-so — rejects the submission if any claim is
uncited or cites an id that isn't in the ledger:
def validate_attribution(analysis, ledger):
for claim in analysis.all_claims():
if not claim.cite_ids:
violations.append(f"Uncited claim: {claim.statement!r}")
for cid in claim.cite_ids:
if cid not in ledger: # hallucinated citation
violations.append(f"Unresolvable citation {cid!r}")
Feed it a fabricated citation and it bounces:
accepted: False
REJECTED -> Unresolvable citation 'PMID:00000000' in claim: 'AI is 99% accurate (fabricated)'
This is the concrete implementation of "every claim must cite a verifiable source." The model is free to reason, but it cannot ship a statement the harness can't trace back to a real fetched record. On the featured run the artifact passed with 22 claims / 50 citations / 0 violations — and every one of those citations resolves to a clickable PubMed or openFDA URL in the References section.
3. Human-in-the-loop. The run writes a gap_analysis.draft.md first.
Nothing is finalized until a human approves (--approve), modeling a regulatory
sign-off gate.
What the Orchestrator Concluded
The output isn't the point — the traceability is — but the analysis is genuinely useful precisely because it's grounded. A few of its gap findings, each carrying real citations:
- Subsolid-nodule performance is a recognized weakness and high clinical
stakes for indolent adenocarcinoma, yet the strongest current benchmark
evidence centers on solid indeterminate nodules — a validated evidence gap.
[NOTE:subsolid-nodules] [PMID:42340186] - Intended-use boundary. Detection, malignancy-risk estimation, and
follow-up recommendation are three different intended uses with escalating
regulatory weight — and the predicate landscape's split across OEB / POK / JAK
product codes confirms the boundary is consequential.
[NOTE:intended-use-boundary] [K251203] [K251769] [K242188] - Post-market blind spot. Because MAUDE is so sparse and acronym-collided, a targeted post-market surveillance strategy (by product code, not "CAD" keyword) is needed — flagged honestly as an open question rather than papered over.
Two Ways to Orchestrate
The repo ships two orchestrators, and contrasting them is instructive. The
faithful version (--agentic) is what the blog describes: the orchestrator
model uses the Agent SDK's Task tool to dispatch three tool-restricted
sub-agents, each of which can call exactly one skill. The deterministic
sidebar calls the four tools in code and makes a single synthesis call. The
faithful version is truer to the "society of agents" framing; the deterministic
one is cheaper and perfectly reproducible. For a Phase 01 aid that a human will
review anyway, reproducibility is worth a lot — a useful reminder that "agentic"
is a dial, not a binary.
Takeaways
- The Phase 01 pattern is buildable today, with free public data, in a few hundred lines. The blog's design survived contact with reality.
- The guardrails are the product. A gap analysis nobody can trust is worse than none; the citation ledger is what makes the output auditable.
- The friction is in the data, not the agents. MAUDE's sparseness and the CAD/CAM collision were the real obstacles — and surfacing that is itself a valid Phase 01 output.
Reproduce It
The whole thing is a pip install and one command. The three data sources are
free and keyless, so the only credential you need is one to authenticate the
Claude model — and you can use a plain ANTHROPIC_API_KEY, no Claude Code
subscription or interactive login required:
git clone https://github.com/andinet/nodule-scout && cd nodule-scout
pip install -e .
cp .env.example .env # then set ANTHROPIC_API_KEY=sk-ant-...
# (or, if you use Claude Code, just `claude` to log in)
python run.py --approve # → outputs/gap_analysis.md
The run prints which auth it picked up (auth: using ANTHROPIC_API_KEY…), fetches
the live evidence, and writes the cited artifact. The tests — pytest — need no
key at all: they hit the public APIs anonymously and exercise the guardrails
offline. Everything you've read above came out of that one command.
Next in the series: Phase 02 (Requirements & SRS), where the guardrails escalate because the artifacts start feeding directly into regulated documentation.
References
Every citation in the generated artifact resolves to a live URL; the sources referenced in this post are:
- PubMed — PMID 42340186, the LUNA25 challenge (AI vs. radiologists on indeterminate-nodule malignancy risk): https://pubmed.ncbi.nlm.nih.gov/42340186/
- FDA 510(k) predicate clearances — the cited devices whose product-code split (OEB / POK / JAK) shows the intended-use boundary is consequential: K254075 (Fujifilm Synapse Lung Nodule AI) · K251769 (RevealAI-Lung) · K251203 (Coreline AVIEW Lung Nodule CAD) · K242188 (Riverain ClearRead CT)
- FDA MAUDE — adverse-event report 11195257 (openFDA device/event): https://api.fda.gov/device/event.json?search=mdr_report_key:11195257
- Advisory notes —
NOTE:subsolid-nodulesandNOTE:intended-use-boundaryare entries in a synthetic clinical-advisory corpus shipped in the repo (data/advisory_notes/), not external sources.
Code, tests, and a committed sample run: github.com/andinet/nodule-scout.
The views, opinions, and technical perspectives expressed in this article are entirely my own and do not represent, reflect, or imply the positions, strategies, or endorsements of my employer or any organization I am affiliated with.